I. Bases de datos
Una base de datos se puede percibir como un gran almacén de datos, que se utiliza al mismo tiempo por distintos usuarios.
En relevante tanto a nivel persona (permite desarrollar software sin estar en una empresa), como a nivel empresa (análisis de datos).
Un registro es una fila o dupla: Registro = Filas = Dupla Los componentes de las bases de datos son:
- Datos
- Software
- Recursos humanos
1.1 Back-end
Administración de los datos en relación con la interacción con los usuarios. Es vital para el funcionamiento de las funciones de una página o programa.
1.2 Tipos de atributos
- Mono-valuados: Tienen un único valor asociado a una entidad, y que solo se puede tener uno. Ejemplo: Matrícula, Apellidos (paterno y materno)
- Multivaluados: Tienen un conjunto de valores para una entidad específica. Ejemplo: teléfonos, correos
- Compuestos: Son atributos que se pueden descomponer en elementos más pequeños. Ejemplo: Dirección, Nombre
- Derivados: Sus atributos se pueden obtener en base a otros atributos relacionados. Ejemplo: El atributo Edad se deriva del atributo Fecha de nacimiento y Fecha actual
- Nulo: Cuando una entidad no tiene un valor para un atributo. Ejemplo: Atributos opcionales que no tienen respuesta en formularios
1.3 Cardinalidad
Expresa las relaciones entre entidades, mediante el número de entidades a las que otra entidad puede estar relacionada. Ejemplo: (Entidad1: Docente, Entidad2: Curso. Las relaciones son la cardinalidad) Tipos:
- 1 a muchos: 1 docente puede impartir varios cursos (1_m) o (1_asterisco)
- 1 a 1: 1 docente puede impartir un curso (1_1)
- muchos a muchos: un docente puede impartir varios cursos y varios cursos pueden ser impartidos por muchos docentes (n:n) ó (n_m)
1.4 Tipos de bases de datos
Modelo de bases de datos relacionales
- Se organizan en tablas con relaciones definidas mediante claves primarias y foráneas.
- Entre sus ventajas se encuentra: Estandarizado, eficiente.
Modelo de datos jerárquico
- Organización en forma de árbol, con un nodo raíz y niveles
- Tienen relación padre-hijo
Modelo de datos en red
- Relaciones complejas no jerárquicas
- Complejo de usar
Modelo de datos orientado a objetos
- Se usa el encapsulamiento, donde se ocultan detalles internos, exponiendo sólo los métodos para acceder a ellos. (Público, Privado, Protegido)
- Los objetos pueden heredar propiedades y métodos, promoviendo la reutilización de código
- Los objetos se pueden comportar de diversas maneras según su tipo, aumentando la flexibilidad. El polimorfismo establece que un objeto sea abstracto, de manera que otros sean lo que lo definan
II. Diagramas representativos
2.1 Diagrama de entidad relación
Es la representación gráfica de cada uno de los requerimientos representados en entidades, atributos y relaciones.
- Entidad: Es un objeto o una cosa del mundo real que es distinguible de los demás objetos. Ejemplo: Mesa
- Atributos: Son las características de a entidad. Ejemplo: Material
- Relaciones: Cardinalidad
| Figura | Representación |
|---|---|
| Rectángulo | Entidades. Ejemplo: Cliente, Proveedores… |
| Elipse | Atributos: Puntuado derivadas, doble para multivaluado, subrayado es clave primaria. Ejemplo: Teléfono |
| Rombo | Conjunto de Relaciones. Ejemplo: Compra, Vende, Atiende… |
2.2 Diagrama relacional
Es una representación en forma de tablas que representa una base de datos relacional, donde sus columnas (atributos) y las relaciones entre ellas mediante llaves foráneas y primarias.
- Una base de datos es un conjunto de tablas.
- Una tabla está compuesta por registros denominados también como filas o duplas.
- Un registro está compuesto por campos a los que también se llaman columnas o atributos.
- Las claves nos permiten acceder a los registros de una tabla.
- Una clave candidata es un campo o una combinación de campos que identifican un atributo de forma exclusiva.
- Una clave primaria es una clave candidata que ha sido designada para identificar de forma única los registros de una tabla.
- Las bases de datos relacionales son aquellas en las que cualquier tabla puede relacionarse con otra tabla a través de claves.
Notas: Si cambian los datos, pueden tener su tabla aparte.
Tipos de claves en un diagrama relacional
Claves primarias (llaves primarias)
Atributo que garantiza que cada entidad es única. Las claves candidatas son aquellas que pueden cumplir este propósito. Las claves primarias son las elegidas. Ejemplo: Matrícula, CURP, RFC
- Cada entidad debe tener una clave primaria.
- Las claves primarias van subrayadas.
Claves candidatas
Son aquellas llaves que son candidatas a ser clave primaria.
Claves foráneas
Una clave foránea o externa se compone de uno o varios atributos, que forman una clave primaria en otra tabla a la cual se desea relacionar.
- Se puede cambiar el nombre de la clave foránea, no necesariamente debe ser la misma que la clave primaria de la tabla con la que se relaciona.
III. Normalización
Es la transformación del diseño de la base de datos a uno más simple y estable, sin ambigüedad.
Esto es importante para optimizar y garantizar que no haya ambigüedades (Pérdida de datos, etc.).
3.1 Regla/Forma 1
Una tabla está en Primera Forma Normal (1NF) si cumple con lo siguiente:
- Atomicidad: Cada celda contiene un único valor atómico (no listas, conjuntos ni estructuras anidadas).
- Clave primaria: Debe existir una clave primaria que identifique unívocamente cada fila.
- Sin duplicados: No debe haber filas duplicadas.
- Uniformidad: Cada columna debe contener valores de un solo tipo de dato (coherentes para cada fila).
Recomendación: Los datos compuestos (como nombres completos) o valores múltiples (como listas de teléfonos) deben descomponerse en datos atómicos. No se permiten rangos ni conjuntos de valores en una celda.
3.2 Regla/Forma 2
Una tabla está en Segunda Forma Normal (2NF) si:
- Está en 1NF.
- Sin dependencias parciales Ocurren cuando un atributo depende de parte de una clave primaria compuesta y no de la clave primaria completa. Es decir, se crean tablas independientes para conjuntos de valores que se apliquen a varios registros.
- Llaves foráneas: Las tablas se relacionan mediante llaves foráneas.
3.3 Regla/Forma 3
Una tabla está en Tercera Forma Normal (3NF) si:
- Está en 2NF.
- Sin dependencias transitivas: Los atributos no clave dependen exclusivamente de la clave primaria y no de otros atributos no clave. Es decir, al tener dos entidades conectadas de muchos a muchos, se crea una tabla intermedia que incluye las claves primarias de ambas tablas como claves foráneas y con el nombre de ambas entidades.
- Se separan los catálogos: Surge el catálogo, donde los datos ya están definidos, como tipos de categorías. (Dato de un atributo, que tiene un rango limitado).
3.4 Regla/Forma 3.5 Boyce Codd
La Forma Normal de Boyce-Codd es una versión más estricta de la 3NF, y se cumple si:
- Está en 3NF.
- Cada determinante es una clave candidata: Cada atributo que determine a otro debe ser una clave candidata, o debe dividirse la tabla si causa dependencias funcionales. Es decir, si para cada dependencia funcional X - Y en la tabla, el conjunto X es una superclave. Una superclave es un conjunto de uno o más atributos de una tabla que puede identificar de manera única todas las filas de las tablas.
- Sin dependencias funcionales: No deben existir relaciones entre atributos fuera de las claves candidatas.
- En general, todos los atributos tienen que depender de la superclave. Ejemplo: Si tenemos la tabla Estudiantes: id_estudiante, nombreEstudiante, nombre_curso, profesor. Los datos de curso y el profesor no van en la tabla Estudiantes ya que no dependen de la superclave (id_estudiante), por lo que se separan en otra tabla donde se conecten.
3.5 Regla/Forma 4
Una tabla está en Cuarta Forma Normal (4NF) si:
- Está en 3.5NF.
- Sin dependencias multivaluadas: En una tabla sólo pueden haber 2 llaves foráneas. Se puede resolver al separar la tercera tabla y conectarla con otra. Ejemplo: Se tienen varias tablas que se relacionan a una sola y esto crea muchas combinaciones posibles, que pueden confundir, como un juguete que tiene aspectos de las tablas materiales colores tamaños, venta etc..
3.6 Regla/Forma 5
Una tabla está en Quinta Forma Normal (5NF) si:
- Está en 5NF.
- Sin dependencias de unión: Depuración, es decir, se optimizan las tablas para eliminar redundancias entre las tablas con relaciones.
3.7 Notas de normalización
- Pensar en cómo interaccionan los datos con el front-end.
- Los datos generados automáticamente, o que se ponen con un menú específico en la interfaz, no se coloca como tabla. Ejemplo: Fecha, en caso de que el usuario pueda elegirla de un calendario, ya que tiene un formato estándar. Es decir, si un dato se consigue en la interfaz, mediante un algoritmo programado y no de una base de datos. Por lo tanto, no va una tabla.
Dependencia transitiva
Se da al romper la ambigüedad generada por dos elementos que dependen entre ellos.
Creación de tablas normalizadas en diagrama relacional
¿Cuándo se separa un atributo de una tabla?
Depende mucho de los requerimientos pero para darse una idea inicial:
- ¿El valor del atributo cambia con cierta frecuencia?
- Sí: Se separa de la tabla.
- No:
- ¿Varias instancias del mismo elemento podrían compartir un mismo valor?
- Si:
- No: Se queda en la tabla.
- ¿El atributo se trata de un catálogo? (Datos que pueden representarse en una lista o que tienen un rango de datos ya establecido)
- Si: Se separa de la tabla.
- No: Se queda en la tabla. (Ejemplo: Nombre)
IV. Diccionario de datos
Es un repositorio descentralizado de información sobre los datos que se utilizan en un sistema de gestión de bases de datos o en una aplicación.
Contiene descripciones detalladas en forma de tabla, de las variables, tablas, atributos y relaciones dentro de un sistema de base de datos.
Se debe considerar el front-end.
4.1 Datos del diccionario
- Nombre del campo o atributo
- Tipo de dato
- Tamaño del campo
- Descripción que explique el dato
- Valor permitido válido para ese atributo (Dominio)
- Relaciones del dato con otros (Claves foráneas, etc.)
- Reglas de validación para verificar que el dato sea correcto (Ejemplo: no se permiten valores negativos)
4.2 Importancia
- Análisis de requerimientos. Ayuda a comprender los datos necesarios para una solución
- Diseño de bases de datos
- Desarrollo
- Mantenimiento
V. Álgebra relacional
Las bases de datos relacionales requieren de un conjunto de operaciones que permiten manipular la base de datos. Date (2001) menciona que el álgebra relacional es un conjunto de operadores que toman sus relaciones como sus operandos y regresan una relación como resultado.
5.1 Operadores relacionales
- σ (sigma): Representa la operación de selección, que filtra las filas de una relación basándose en una condición.
- π (pi): Representa la operación de proyección, que selecciona columnas específicas de una relación.
- ∪ (unión): Representa la unión de dos relaciones.
5.2 Operadores de condición
- < (Menor que): Compara si un valor es menor que otro.
- > (Mayor que): Compara si un valor es mayor que otro.
- <= (Menor o igual a que): Compara si un valor es menor o igual a otro.
- >= (Mayor o igual a que): Compara si un valor es mayor o igual a otro.
- = (Igual a): Verifica si dos valores son iguales.
5.3 Representación de una expresión
Se puede representar de 3 maneras:
- Texto: Descripción.
Muestra todos los datos de empleados que tengan un salario de 4000
- Álgebra Relacional: Expresión Relacional. $$\sigma({\pi\text{salario} = 4000} (\text{Empleados})) $$
- Código SQL: Código.
SELECT * FROM Empleados WHERE salario = 4000;
VI. Microsoft SQL
El SQL (Lenguaje Estructurado de Consultas) es un lenguaje declarativo basado en el modelo relacional, es decir, se indican instrucciones y la acción que realizarán sobre una base de datos relacional.
6.1 Categorías de SQL
- Lenguaje de definición de datos (DDL, Data Definition Language): Son instrucciones que se utilizan para crear, modificar y borrar objetos de la base de datos, como tablas, vistas, esquemas, dominios, activadores y procedimientos almacenados.
- Lenguaje de control de datos (DCL, Data Control Language): Son instrucciones que permiten controlar quién o qué tiene acceso a objetos específicos de la base de datos. Dentro de estas instrucciones se pueden encontrar aquellas asociadas a la administración de usuarios, para otorgar o revocar permisos a objetos de las bases de datos.
- Lenguaje de manipulación de datos (DML, Data Manipulation Language): Son instrucciones que se utilizan para recuperar, agregar, modificar y borrar datos almacenados en la base de datos.
6.2 Instalación y uso
- En la página Microsoft SQL se elige la versión express, instalación personalizada, instalar, New standalone installation, aceptar e instalar
- Quitar selección de Azure, y Machine Learning y todo next
- Install SQL server management tools, Descargar los ssms
- Cerrar todo y abrir SQL Server Management Studio 20
- Colocar opcional, y conectar
- Al abrir dar conectar
- En la barra, New Query
- Seleccionar primera línea (CREATE DATABASE mydb;) y Execute, lo mismo con la segunda línea (Use mydb;)
Notas de programar en SQL
- Declarar cada FK como una variable más
- Ejecutar cada tabla, primero escribir y ejecutar las tablas de las que otras dependen
- Cada insert debe seguir la jerarquía con la que se crearon las tablas
- Si se puso una numeración automática (IDENTITY(1,1)) en el id de una tabla, cuando se inserten datos no se colocan los id. Si es foránea si se pone, para saber con quién se conecta.
VII. Estructura y configuración inicial en SQL Server
7.1 Operaciones básicas de SQL
- CREATE DATABASE: Crea una nueva base de datos
- USE: Selecciona la base de datos en la que deseas trabajar. Después de ejecutar este comando, todas las operaciones de SQL se aplicarán a la base de datos seleccionada.
- DROP DATABASE Elimina por completo una base de datos.
- CREATE TABLE: Crea una nueva tabla. Al definirla, se especifican las columnas, tipos de datos y restricciones para almacenar información estructurada.
- DROP TABLE: Elimina la tabla que se seleccione
- INSERT: Permite agregar una nueva fila o registro en una tabla. Se puede especificar una lista de columnas y valores correspondientes.
- UPDATE: Modifica los datos de las filas en una tabla. Permite actualizar uno o más valores en registros específicos utilizando una cláusula
WHEREpara limitar las filas afectadas. - SELECT: Corresponde a la operación de proyección del álgebra relacional, se utiliza para listar los atributos de una consulta.
- FROM: Indica la tabla o tablas desde las cuales se extraerán los datos.
- WHERE: Filtra los registros en función de una condición dada, similar a la operación de selección en el álgebra relacional.
- INNER JOIN … ON: Combina filas de dos o más tablas en función de una condición de igualdad especificada en la cláusula ON. Solo devuelve las filas donde existe una coincidencia en ambas tablas.
7.2 Creación de los elementos iniciales
- Crear y usar la base de datos
CREATE DATABASE NombreDB;
USE NombreDB;
- Crear tablas. Aquellas que no tienen llave foránea van primero.
CREATE TABLE Departamentos
(
id_departamento INT IDENTITY(1,1) PRIMARY KEY,
atributo VARCHAR(50),
atributo2 DATE,
atributo3 FLOAT(9),
atributo4 INT
);
CREATE TABLE Empleados
(
id_empleado INT IDENTITY(1,1) PRIMARY KEY,
atributo VARCHAR(50),
atributo2 DATE,
atributo3 FLOAT(9),
atributo4 INT,
id_departamento INT,
FOREIGN KEY (id_departamento) REFERENCES Departamentos(id_departamento)
);
7.3 Manipulaciones de datos en tablas
INSERT
Insertar valores.
Ejemplo
INSERT INTO Departamentos
VALUES
('Sistemas', 2025-01-15, 50.2, 30),
('RH', 2025-03-09, 50.2, 30);
INSERT INTO Empleados
VALUES
('Ernesto', 2025-01-15, 25.5, 10, 1),
('Laura', 2025-03-09, 25.5, 10, 2);
UPDATE
Actualizar valores. No omitir WHERE ya que sino se actualizarán todos los registros de la tabla.
Ejemplo
UPDATE Productos
SET nombreProducto = 'Frijol', precio = 19.99
WHERE id_producto = 3;
DELETE
Borra valores. No omitir WHERE ya que sino se eliminarán todos los registros de la tabla.
Ejemplo
DELETE FROM Productos
WHERE idProducto = 5;
DROP
Eliminar una tabla. No se podrá eliminar si hay otra tabla que dependa de esta.
Ejemplo
DROP TABLE Productos;
Eliminar una base de datos. No se puede eliminar la base de datos si está en uso, por lo que primero se debe usar otra tabla antes.
Ejemplo
USE master;
DROP DATABASE NombreBD;
7.4 Notas generales de SQL Server
- Declarar cada FK como una variable más
- Ejecutar cada tabla, primero escribir y ejecutar las tablas de las que otras dependen
- Cada insert debe seguir la jerarquía con la que se crearon las tablas
- Si se puso una numeración automática (IDENTITY(1,1)) en el id de una tabla, cuando se inserten datos no se colocan los id. Si es foránea si se pone, para saber con quién se conecta.
VIII. Consultas
8.1 Consultas básicas
Se usa SELECT para iniciar, * para hacer una selección global o se especifican los datos para especificar la búsqueda. Adicionalmente se usa FROM para especificar la tabla y WHERE para especificar una condición.
Ejemplos
- Consulta todos los archivos y sus características
SELECT * FROM sys.master_files;
- Consulta todas las bases de datos
SELECT * FROM sys.databases;
- Consulta las tablas, se cambia el nombre de la DB que se quiere ver
SELECT object_id, '['+SCHEMA_NAME(schema_id)+'].['+name+']'
AS [schema_table], max_column_id_used, type, type_desc, create_date, modify_date, lock_escalation_desc
FROM sys.tables;
- Consulta e texto o código fuente de un objeto en la base de datos, como una vista, procedimiento almacenado, función o disparador
sp_helpText contarDepartamentos;
- Consulta todo de los clientes con apellido paterno ‘Martinez’
SELECT * FROM Clientes WHERE apellidoP = 'Martinez';
- Consulta el precio y las ventas de los productos de color ‘azul’
SELECT precio, ventas FROM Productos WHERE color = 'azul';
8.2 Uso de JOIN
INNER JOIN
Combina filas de dos o más tablas en función de una condición de igualdad especificada en la cláusula ON. Solo devuelve las filas donde existe una coincidencia en ambas tablas. Se toma en cuenta la llave primaria y la foránea.
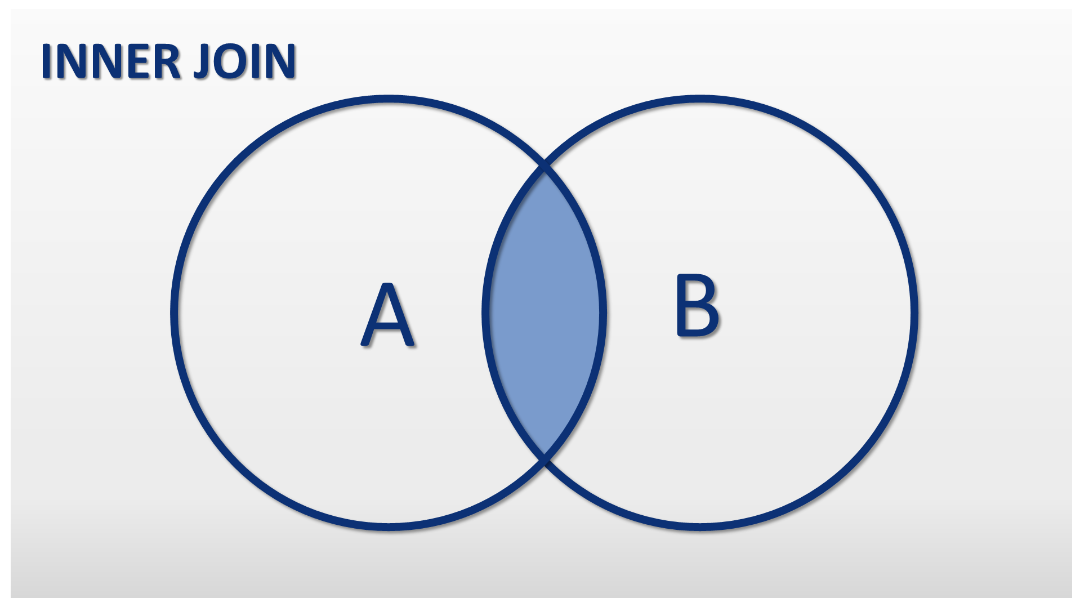
Sintaxis
SELECT columnas FROM TablaA INNER JOIN TablaB ON TablaA.id_tablaA = TablaB.id_tablaA WHERE columna9 = 'valor'
Ejemplos
- Consulta los nombres de los clientes y las fechas de los pedidos
SELECT Clientes.nombre, Pedidos.fecha FROM Clientes INNER JOIN Pedidos ON Clientes.id_cliente = Pedidos.id_cliente;
- Consulta el nombre del producto, la cantidad, la fecha y el nombre del cliente en 4 tablas
SELECT p.nombreProducto, dp.cantidad, pe.fecha, cl.nombre FROM Productos p INNER JOIN DetallesPedidos dp ON p.id_producto = dp.id_producto INNER JOIN Pedidos pe ON dp.id_pedido = pe.id_pedido INNER JOIN Clientes cl ON pe.id_pedido = cl.id_cliente;
LEFT JOIN
EI LEFT JOIN devuelve todas las filas de la tabla de la izquierda (en
este caso clientes), y las filas coincidentes de la tabla de la derecha
(pedidos). Si no hay coincidencia, el resultado mostrará NULL en las
columnas de la tabla de la derecha.
Sintaxis
SELECT columnas FROM TablaA LEFT JOIN TablaB ON TablaA.id_tablaA = TablaB.id_tablaA WHERE columna9 = 'valor'
Ejemplo
- En este caso la consulta de Promedio de ventas por cliente muestra únicamente los datos que se especifican y que coinciden en la tabla de la izquierda y pone en NULL las de la derecha que no.
SELECT Clientes.nombre, AVG(totalVenta) AS promedioVenta FROM Clientes LEFT JOIN Ventas ON Clientes.id_cliente = Ventas.id_cliente GROUP BY nombre;
RIGHT JOIN
EI RIGHT JOIN es lo contrario al LEFT JOIN. Devuelve todas las filas de
la tabla de la derecha (pedidos), y las filas coincidentes de la tabla de
la izquierda (clientes). Si no hay coincidencia, se mostrarán NULL en
las columnas de la tabla de la izquierda.
Sintaxis
SELECT columnas FROM TablaA RIGHT JOIN TablaB ON TablaA.id_tablaA = TablaB.id_tablaA WHERE columna9 = 'valor'
Ejemplo
- En este caso la consulta de Promedio de ventas por cliente muestra únicamente los datos que se especifican y que coinciden en la tabla de la derecha y pone en NULL las de la izquierda que no.
SELECT Clientes.nombre, AVG(totalVenta) AS promedioVenta FROM Clientes RIGHT JOIN Ventas ON Clientes.id_cliente = Ventas.id_cliente GROUP BY nombre;
FULL JOIN
FULL JOIN Devuelve filas cuando hay una coincidencia en una de las tablas, o ambas.
Sintaxis
SELECT columnas FROM TablaA FULL JOIN TablaB ON TablaA.id_tablaA = TablaB.id_tablaA WHERE columna9 = 'valor'
Ejemplo
- En este caso se muestra tanto lo que coincide como lo que no
SELECT Clientes.nombre, AVG(totalVenta) AS promedioVenta FROM Clientes FULL JOIN Ventas ON Clientes.id_cliente = Ventas.id_cliente GROUP BY nombre;
CROSS JOIN
Devuelve el producto cartesiano de ambas tablas, es decir, todas las combinaciones posibles de filas.
Sintaxis
SELECT * FROM Tabla1 CROSS JOIN Tabla2;
Ejemplo
- En este caso se muestra el producto cartesiano de todos los datos de Clientes y Ventas
SELECT * FROM Clientes CROSS JOIN Ventas;
8.3 Funciones
CONCAT(X, Y)
Concatena dos cadenas de texto.
Ejemplo
- Selecciona el
iddeempleadoy elnombreconapellidoy mostrar comonombreCompleto, de la tablaempleados
SELECT id_empleado, CONCAT(nombre, ' ', apellido) AS nombreCompleto FROM Empleados;
LENGTH(X)
Devuelve la longitud de la cadena X.
Ejemplo
- Muestra el nombre y el número de caracteres
SELECT id_empleado, nombre, LEN(nombre) AS longitudNombre FROM Empleados;
SUBSTRING(X, Start, Length)
Extrae una sub-cadena de X a partir de la posición Start con la longitud indicada.
Ejemplo
- Muestra el nombre y la versión en sub-cadena
SELECT id_empleado, nombre, SUBSTRING(nombre, 1, 3) AS subcadena FROM Empleados;
UPPER(X) / LOWER(X)
Convierte X a mayúsculas o minúsculas, respectivamente.
Ejemplos
- Muestra el nombre y en mayúsculas
SELECT id_empleado, nombre, UPPER(nombre) AS nombreMayusculas FROM Empleados;
- Muestra el nombre y en minúsculas
SELECT id_empleado, nombre, LOWER(nombre) AS nombreMinusculas FROM Empleados;
DATE
Ejemplos
- Obtener la fecha
SELECT GETDATE() AS fechaHoraActual;
- Agregar a la fecha 5 días
SELECT DATEADD(DAY, 5, '2025-02-03') AS nuevaFecha;
- Obtiene la diferencia en días de una fecha menos otra
SELECT DATEDIFF(DAY, '2025-01-01', '2025-02-03') AS diferenciaDias;
- Obtiene el año, mes y día separándolos de la fecha deseada
SELECT
YEAR('2025-02-03') AS anio,
MONTH('2025-02-03') AS mes,
DAY('2025-02-03') AS dia;
- Obtiene la diferencia en años de una fecha menos otra
SELECT DATEDIFF(DAY, '2020-01-01', '2025-02-03')/365.25 AS diferenciaAnios;
- Añade 10 días y resta 3 meses a la fecha deseada
SELECT
DATEADD(DAY, 10, '2025-02-03') AS nuevaFechaConDias,
DATEADD(MONTH, -3, '2025-02-03') AS nuevaFechaConMes;
8.4 Operaciones
COUNT(*)
Cuenta el número total de registros de una tabla.
Ejemplo
- Cuenta los registros en empleados.
SELECT COUNT(*) AS totalEmpleados FROM Empleados;
SUM(columna)
Suma los valores de una columna numérica. Se pueden usar otros operadores para hacer operaciones dentro. Funciona mejor con INT.
Ejemplo
- Suma los montos de ventas
SELECT SUM(monto) AS totalVentasMonto FROM Ventas;
AVG(columna)
Calcula el promedio de los valores de una columna numérica.
Ejemplo
- Promedia los montos de las ventas
SELECT AVG(monto) AS promedioMonto FROM Ventas;
MIN(columna)
Devuelve el valor mínimo en una columna.
Ejemplo
- Obtiene el monto más bajo de las ventas.
SELECT MIN(monto) AS montoMinimoVenta FROM Ventas;
MAX(columna)
Devuelve el valor máximo en una columna.
Ejemplo
- Obtiene el monto más alto de las ventas.
SELECT MAX(monto) AS montoMinimoVenta FROM Ventas;
Uso de GROUP BY
Agrupa registros por una columna y cuenta cuántos existen en cada grupo. Se usa cuando se requieren dos o más registros.
Ejemplo
- Obtiene las ventas por producto
SELECT nombre, COUNT(*) AS cantidadVentas FROM Productos GROUP BY nombre;
Dependiendo del elemento con el que se agrupa, se mostrarán diferentes resultados, y es posible agrupar por varios filtros (Se separan con una coma). Si se agrupa por id se mostrará solo una vez cada registro con ese id aunque aparezcan varias veces.
Uso de ORDER BY
El ORDER BY se usa para ordenar los resultados de una consulta según una o varias columnas. Se puede especificar el orden:
- ASC: ascendente, por defecto.
- DESC: descendente.
Ejemplos
- Obtiene la lista de productos ordenada alfabéticamente:
SELECT nombre, precio
FROM Productos
ORDER BY nombre ASC;
- Obtiene los productos más caros primero:
SELECT nombre, precio
FROM Productos
ORDER BY precio DESC;
Relación con GROUP BY
Cuando se usa GROUP BY, el ORDER BY permite ordenar los grupos generados según los valores agregados.
Ejemplo
- Obtiene las ventas por producto y las ordena de mayor a menor:
SELECT nombre, COUNT(*) AS cantidadVentas
FROM Productos
GROUP BY nombre
ORDER BY cantidadVentas DESC;
8.5 Vistas
Las vistas en SQL son objetos virtuales que nos permiten acceder y manipular datos almacenados en una o varias tablas como si fueran tablas individuales. Sus ventajas son:
- Se simplifican las consultas
- Se organizan los datos y mejora el rendimiento.
- Son más seguras porque ya no se ve el join con los datos, solo se verá el nombre de la vista.
Sintaxis básica de una vista
- Crear una vista
CREATE VIEW nombre_vista
AS consulta_deseada;
- Consultar una vista
SELECT * FROM nombre_vista;
- Modificar una vista
CREATE VIEW nombre_vista
AS consulta_deseada;
ALTER VIEW nombre_vista
AS consulta_nueva;
Ejemplo
- Vista que muestra todos los empleados del departamento de sistemas y de Puebla
CREATE VIEW empleadosSistemasPuebla
AS
SELECT Personas.nombrePersona
FROM Personas INNER JOIN Departamentos
ON Personas.id_departamento = Departamentos.id_departamento INNER JOIN DepartamentosEstados
ON Departamentos.id_departamento = DepartamentosEstados.id_departamento INNER JOIN Estados
ON DepartamentosEstados.id_estado = Estados.id_estado
WHERE Departamentos.nombreDepartamento = 'Sistemas' AND Estados.nombreEstado = 'Puebla';
SELECT * FROM empleadosSistemasPuebla;
Cifrado de vistas
El cifrado de vistas se usa para mantener la confidencialidad del código, especialmente si se contiene lógica o procesos sensibles.
Ejemplo
- Se crea una nueva vista con cifrado
CREATE VIEW nombre_vista WITH ENCRYPTION
AS consulta_deseada;
- Se modifica una vista para que tenga cifrado
CREATE VIEW nombre_vista
AS consulta_deseada;
ALTER VIEW nombre_vista WITH ENCRYPTION
AS consulta_nueva;
Para comprobar si está cifrada, se utiliza sp_helpText.
IX. Automatización y seguridad
9.1 Procedimientos almacenados
Los stored procedures permiten agilizar los procesos de consulta de datos, aumentar la seguridad, reutilizar código y permiten un desarrollo de software más ágil. Dentro de SQL Server se les considera como un grupo de una o varias instrucciones Transact-SQL, mientras que en Microsoft .NET Framework se trata de una referencia a un método de Common Runtime Language (CLR).
Los SP contienen instrucciones de programación que realizan operaciones en la base de datos, como llamar a otros procedimientos, devolver un valor de estado o realizar una llamada para indicar si la operación se ha realizado correctamente o se han producido errores y el motivo de estos.
Ejemplos
- SP que inserta un registro en la tabla
Personas
CREATE PROCEDURE sp_createPersona
(
@nombrePersona VARCHAR(100),
@apellidoP VARCHAR(100),
@apellidoM VARCHAR(100),
@genero VARCHAR(100),
@correo VARCHAR(100),
@puesto VARCHAR(100),
@telefono VARCHAR(10),
@edad INT,
@sueldo INT,
@id_departamento INT
)
AS
BEGIN
INSERT INTO Personas
VALUES (@nombrePersona, @apellidoP, @apellidoM, @genero, @correo, @puesto, @telefono, @edad, @sueldo, @id_departamento);
END
EXECUTE sp_createPersona 'Hernán', 'Lopez', 'Cortés', 'Masculino', 'hernan@gmail.com', 'Sistemas', '2255487887', 38, 27000, 2;
- SP que actualiza un registro en la tabla
Personas
CREATE PROCEDURE sp_updatePersona
(
@id_persona INT,
@nombrePersona VARCHAR(100),
@apellidoP VARCHAR(100),
@apellidoM VARCHAR(100),
@genero VARCHAR(100),
@correo VARCHAR(100),
@puesto VARCHAR(100),
@telefono VARCHAR(10),
@edad INT,
@sueldo INT,
@id_departamento INT
)
AS
BEGIN
UPDATE Personas
SET
nombrePersona = @nombrePersona,
apellidoP = @apellidoP,
apellidoM = @apellidoM,
genero = @genero,
correo = @correo,
puesto = @puesto,
telefono = @telefono,
edad = @edad,
sueldo = @sueldo,
id_departamento = @id_departamento
WHERE id_persona = @id_persona;
END
EXECUTE sp_updatePersona 2, 'Laura', 'Sierra', 'Cayo', 'Femenino', 'laura@gmail.com', 'Administrador', '2255489741', 32, 20000, 1;
- SP que consulta por el nombre de una persona y además muestra el departamento y estados con el que está relacionada mediante un
INNER JOIN
CREATE PROCEDURE sp_searchPersona
(
@nombrePersona VARCHAR(100)
)
AS
BEGIN
SELECT Personas.nombrePersona, Departamentos.nombreDepartamento, Estados.nombreEstado
FROM Personas INNER JOIN Departamentos
ON Personas.id_departamento = Departamentos.id_departamento INNER JOIN DepartamentosEstados
ON Departamentos.id_departamento = DepartamentosEstados.id_departamento INNER JOIN Estados
ON DepartamentosEstados.id_estado = Estados.id_estado
WHERE Personas.nombrePersona = @nombrePersona;
END
EXECUTE sp_searchPersona 'Ernesto';
- Eliminar un stored procedure
DROP sp_nombre;
9.2 Checks
El CHECK es una restricción que se utiliza para definir reglas en la inserción de valores de una tabla, asegurando que los valores insertados cumplan ciertas condiciones. Ayuda a mantener la integridad de los datos dentro de la tabla.
Ejemplos
- Creación de una tabla con checks para que el género sea Masculino o Femenino, que la edad sea igual o mayor a 18, que el sueldo sea mayor o igual a 0 después de agregar el IVA del 16% y que el puesto solo sea en Sistemas, Administrador o Contador, Psicología.
CREATE TABLE Personas
(
id_persona INT IDENTITY(1,1) PRIMARY KEY,
nombrePersona VARCHAR(100),
apellidoP VARCHAR(100),
apellidoM VARCHAR(100),
genero VARCHAR(100),
correo VARCHAR(100),
puesto VARCHAR(100),
telefono VARCHAR(10),
edad INT,
sueldo INT,
id_departamento INT,
FOREIGN KEY (id_departamento) REFERENCES Departamentos(id_departamento),
CHECK(genero IN('Masculino', 'Femenino')),
CHECK(edad >= 18),
CHECK(sueldo * 1.16 >= 0),
CHECK(puesto IN('Sistemas', 'Administrador', 'Contador', 'Psicología'))
);
-- Inserción correcta
INSERT INTO Personas VALUES
('Ernesto', 'Silva', 'Ramos', 'Masculino', 'ernesto@gmail.com', 'Sistemas', '2255489090', 38, 27000, 2);
-- Inserción incorrecta por el puesto
INSERT INTO Personas VALUES
('Raúl', 'Lopez', 'Ramos', 'Masculino', 'raul@gmail.com', 'Redes', '2255489090', 38, 27000, 2);
- Tabla donde el estado sea igual a activo y la fecha de salida esté nulo o que el estado sea inactivo y la fecha de salida no esté nulo.
CREATE TABLE Empleados
(
id_empleado INT IDENTITY(1,1) PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
estado VARCHAR(100),
fecha_salida DATE,
CHECK(estado = 'activo' AND fecha_salida IS NULL OR estado = 'inactivo' AND fecha_salida IS NOT NULL)
);
- Tabla donde se verifica que la fecha de nacimiento del empleado sea menor que su fecha de contratación.
CREATE TABLE Empleados
(
id_empleado INT IDENTITY(1,1) PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
estado VARCHAR(100),
fecha_nacimiento DATE,
fecha_contratacion DATE,
CHECK(fecha_nacimiento < fecha_contratacion)
);
- Tabla que verifica que el cargo del empleado no sea de Gerente o que el salario sea menos de 5000.
CREATE TABLE Empleados
(
id_empleado INT IDENTITY(1,1) PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
estado VARCHAR(100),
cargo VARCHAR(100),
salario DECIMAL(10, 2),
CHECK(cargo != 'Gerente' OR salario > 5000)
);
- Tabla que verifica que el salario total sea mayor o igual al salario base
*0.75
CREATE TABLE Empleados
(
id_empleado INT IDENTITY(1,1) PRIMARY KEY,
nombre VARCHAR(100) NOT NULL,
estado VARCHAR(100),
salario_base DECIMAL(10, 2),
salario_total DECIMAL(10, 2),
CHECK(salario_total >= salario_base * 0.75)
);
9.3 Triggers
Un Trigger o disparador es un script que desencadena determinadas acciones de forma automática en las tablas de la base de datos cuando se insertan, modifican y se añaden nuevos datos, lo cual nos ayuda a mejorar la gestión de la BD y aumenta la integridad de la información.
Ventajas:
- Generación automática de datos: Pueden rellenar valores automáticamente al insertar o actualizar registros.
- Integridad referencial: Ayudan a mantener relaciones correctas entre tablas (como validar claves foráneas).
- Registro de actividad: Guardan información de quién hizo qué y cuándo, útil para rastrear acciones.
- Auditoría: Permiten monitorear y registrar cambios importantes en los datos.
- Replicación en tiempo real: Copian datos automáticamente entre tablas cuando hay cambios.
- Control de seguridad: Aplican reglas de acceso o validaciones antes de modificar datos.
- Prevención de errores: Bloquean transacciones que no cumplen ciertas condiciones.
Tipos de triggers
- Disparadores de fila (Row Triggers): Se activan una vez por cada fila afectada en la tabla. Por ejemplo, si una acción modifica 5 filas, el trigger se ejecuta 5 veces, una por cada fila.
- Disparadores de sentencia (Statement Triggers): Se ejecutan una sola vez por operación, sin importar cuántas filas se vean afectadas. Por ejemplo, si se actualizan 100 filas, el trigger se dispara solo una vez.
Tipos de errores en los triggers
RAISERROR se utiliza para generar un mensaje de error desde un procedimiento almacenado, una función o un lote de comandos.
RAISERROR ('Mensaje de error', #, #)
Los números que contiene tienen un significado específico.
Primer parámetro: “qué tan grave el error”
-1Devuelve el valor de gravedad asociado al error.16Es el nivel de gravedad del error. Este nivel va de 0 a 25, donde 0 es un error grave y 25 es un error menor. El nivel 16 indica un error grave, pero uno que no detiene la ejecución o de la instrucción actual.10Indica un error informativo que no afecta la ejecución del lote o la instrucción.20Indica un error crítico que finaliza la conexión de usuario actual.25Indica un error grave que detiene la ejecución del servidor de SQL Server.0Permite a los desarrolladores generar mensajes personalizados sin impacto en la ejecución del lote o instrucción.
Segundo parámetro: “Estado del error”
-1Devuelve el valor de gravedad asociado al error.1El estado es un número de 1 a 127 que proporciona información adicional sobre el error. Puede ser util para distinguir diferentes causas de un mismo error.Estado 1: Se utiliza para un error de división por cero.Estado 2: Se utiliza para un error de validación de entrada.Estado 3: Se utiliza para un error de violación de restricción (por ejemplo, edad no válida).Estado 4: Se utiliza para un error de clave duplicada al intentar insertar registros en una tabla.
Ejemplos:
- Trigger al tratar de eliminar o alterar una tabla con RAISERROR
CREATE TRIGGER TriggerSeguridadD1
ON DATABASE FOR Drop_Table, Alter_Table
AS
BEGIN
RAISERROR ('No se tiene permitido modificar o eliminar una tabla', -1, -1)
ROLLBACK TRANSACTION
END
-- Se prueba el trigger
DROP TABLE Productos;
- Trigger al insertar y actualizar
CREATE TRIGGER actualizarEInsertarDatosDisparador
ON Estados
AFTER INSERT, UPDATE
AS RAISERROR ('Se actualizaron o insertaron los datos', 16, 10);
-- Se prueba el trigger
INSERT INTO Estados
VALUES ('Guadalajara', 4500000);
Ejecución de los triggers
Los triggers se activan automáticamente cuando ocurre una acción en una tabla, como:
- INSERT (cuando se insertan datos)
- UPDATE (cuando se actualizan datos)
- DELETE (cuando se eliminan datos)
Y pueden ejecutarse en dos momentos:
- BEFORE (antes): El trigger se ejecuta antes de que se realice la acción (útil para validar o modificar datos antes del cambio).
- AFTER (después): El trigger se ejecuta después de que se realiza la acción.
Ejemplos:
- Trigger al insertar
CREATE TRIGGER insertarDatosDisparador
ON Estados
AFTER INSERT
AS PRINT ('Se insertó un registro a la tabla de Estados.');
-- Se prueba el trigger
INSERT INTO Estados
VALUES ('Yuacatán', 1500000);
- Trigger al actualizar
CREATE TRIGGER actualizarDatosDisparador
ON Estados
AFTER UPDATE
AS PRINT ('Se actualizó un registro de la tabla de Estados.');
-- Se prueba el trigger
UPDATE Estados
SET nombreEstado = 'Monterrey', noHabitantes = 5800000
WHERE id_estado = 4;
- Trigger al eliminar
CREATE TRIGGER eliminarDatosDisparador
ON Estados
AFTER DELETE
AS PRINT ('Se eliminó un registro de la tabla de Estados.');
-- Se prueba el trigger
DELETE FROM Estados
WHERE id_estado = 2;
- Trigger que reemplaza el nombre del estado por la palabra ’new'
CREATE TRIGGER triggerAfterInsertar
ON Estados
AFTER INSERT
AS
BEGIN
UPDATE Estados
SET nombreEstado = 'New'
WHERE id_estado IN (SELECT id_estado FROM INSERTED)
END
-- Se prueba el trigger
INSERT INTO Estados
VALUES ('Guerrero', 4500000);
- Trigger de Insert de paletas con variables
CREATE TRIGGER tr_InsertarPaleta
ON Paletas
AFTER INSERT
AS
BEGIN
DECLARE @nombre VARCHAR(100);
SELECT @nombre = nombrePaleta FROM INSERTED;
PRINT 'Se ha insertado una nueva paleta: ' + @nombre;
END;
-- Se prueba el trigger
INSERT INTO Paletas VALUES
('Paleta Chocomil', '50', 1.50, 0.80, 1);
- Consultar los trigger de una DB
USE Disparadores
SELECT OBJECT_NAME(parent_id)
AS Parent_Object_Name, *
FROM sys.triggers
- Borrar un trigger
DROP TRIGGER IF EXISTS nombreTrigger;
X. Operaciones avanzadas
10.1 Procedimientos almacenados avanzados
Se pueden declarar variables que almacenen resultados de consultas y permitan realizar operaciones. Así mismo se pueden generar cambios en base a cierta lógica o notificar.
Proceso
- Se crea el PA y se le da un nombre.
- Se colocan los atributos de las tablas relevantes para el proceso.
- Se declaran las variables que vamos a usar (No existen en las tablas).
- Se realiza la selección para invocar los datos necesarios. Asignar esto a una variable.
- Se realiza la lógica requerida con las variables declaradas.
- Se ejecuta.
Ejemplos
Procedimiento para verificar el precio de los productos, si es mayor a 2000 aplicar descuento del 12 %, en caso contrario 2% y también recibir como parámetro la cantidad y regresar el monto total a pagar con descuento
CREATE PROCEDURE SP_TotalConDescuento
(
@producto_id INT,
@cantidad INT
)
AS
BEGIN
DECLARE @precio DECIMAL(10,2);
DECLARE @descuento DECIMAL(10,2);
DECLARE @total DECIMAL(10,2);
SELECT @precio = precio
FROM Productos
WHERE id_producto = @producto_id;
IF @precio > 2000
SET @descuento = 0.88;
ELSE
SET @descuento = 0.98;
SET @total = (@precio * @descuento) * @cantidad;
PRINT 'El total a pagar con descuento es: ' + CAST(@total AS VARCHAR(20));
END
EXECUTE SP_TotalConDescuento 1, 5;
- Validar la existencia de las paletas y aquellas con cantidad mayor a 100 descuento del 3%. Se busca por id.
CREATE PROCEDURE SP_DescuentoPaletas
(
@id_paleta INT
)
AS
BEGIN
DECLARE @cantidad INT;
DECLARE @precio DECIMAL(10,2);
DECLARE @descuento DECIMAL(10,2) = 0.97;
DECLARE @total DECIMAL(10,2);
SELECT @cantidad = cantidad, @precio = precio
FROM Paletas
WHERE id_paleta = @id_paleta;
IF @cantidad > 100
BEGIN
SET @total = (@precio * @descuento);
UPDATE Paletas
SET precio = @total
WHERE id_paleta = @id_paleta;
PRINT 'Se ha aplicado un descuento al precio original del 3%: ' + CAST(@total AS VARCHAR(20));
END
ELSE
BEGIN
PRINT 'El precio actual se mantiene: ' + CAST(@precio AS VARCHAR(20));
END
END
EXECUTE SP_DescuentoPaletas 1;
- Actualización del precio de los que son menores a 50 pesos y actualizarlo con la suma de 20 pesos más. Afecta a todos los datos.
CREATE PROCEDURE SP_AumentarPrecioPaletas
AS
BEGIN
DECLARE @precio DECIMAL(10,2);
DECLARE @totalDescuento DECIMAL(10,2);
SELECT @precio = precio
FROM Paletas;
IF @precio < 50
BEGIN
SET @totalDescuento = (@precio + 50);
UPDATE Paletas
SET precio = @totalDescuento;
PRINT 'Precios actualizados: ' + CAST(@precio AS VARCHAR(20)) + ' -> ' + CAST(@totalDescuento AS VARCHAR(20)) ;
END
ELSE
BEGIN
PRINT 'Los precios actuales se mantienen: ' + CAST(@precio AS VARCHAR(20));
END
END
EXEC SP_AumentarPrecioPaletas;
XI. Configuraciones de SQL Server
11.1 Creación de diagramas
- Crear la base de datos
- Buscar la DB dentro de la lista de la carpeta databases en el lado izquierdo y expandir
- Expandir la carpeta de database diagram y aceptar el mensaje
- click derecho en esa misma carpeta y seleccionar añadir
- Seleccionar todas las tablas al mismo tiempo y seleccionar add
11.2 Backups
En SQL, los respaldos son una parte esencial, ya que permiten recuperar los datos en caso de fallos o pérdidas.
Existen 2 formas de generar un archivo de backup:
Mediante el gestor:
- Crear la base de datos
- Buscar la DB dentro de la lista de la carpeta databases en el lado izquierdo
- Click derecho en la base de datos, Task, Backup
- Configurar el tipo los componentes y el lugar donde se guardará, etc.
Mediante un comando:
BACKUP DATABASE PaleteriaLaMichoacana TO DISK = 'C:\empresa.bak';
11.3 Creación de usuarios y permisos
Dentro de SQL es posible crear usuarios y asignarle permisos según sea necesario.
Ejemplo:
- Creación de dos usuarios
uLecturayuEscrituracon diferentes contraseñas y permisos.
CREATE LOGIN uLectura WITH PASSWORD = 'Segura123';
USE PaleteriaLaMichoacana;
CREATE USER uLectura FOR LOGIN uLectura;
GRANT SELECT TO uLectura;
DENY INSERT, UPDATE, DELETE TO uLectura;
EXEC sp_addrolemember 'db_datareader', 'uLectura';
CREATE LOGIN uEscritura WITH PASSWORD = 'OtraSegura123';
USE PaleteriaLaMichoacana;
CREATE USER uEscritura FOR LOGIN uEscritura;
GRANT SELECT, INSERT, UPDATE, DELETE TO uEscritura;
EXEC sp_addrolemember 'db_datawriter', 'uEscritura';
Para utilizar los usuarios en SQL Server Management Studio 20:
- Crear el usuario y ejecutar los comandos en la base de datos
- Click derecho nombre de MSI SQLEXPRESS en la barra de la izquierda, propiedades, seguridad y seleccionar SQL Server
- En servicios de windows, buscar SQL Server (SQLEXPRESS) y reiniciar el servicio
- Cambiar la autenticación al abrir SQL poner SQL SERVER Auth
- Colocar login y password del usuario deseado
- Seleccionar opcional
- Entrar. Si hacemos uso de la BD podremos manipularla según se configuró el usuario.
11.4 Consideraciones de una BD en producción
- Cada cuanto se respalda, a qué hora
- Autenticación
- Servidor en la nube o físico, cuidar mucho los accesos
Preguntas variadas:
¿Qué es una función en SQL? Es un bloque de código que realiza una tarea específica y devuelve un resultado.
¿Qué es la cardinalidad?
Es la cantidad de relaciones que puede haber entre las filas de dos tablas.
Por ejemplo:
- Uno a uno
- Uno a muchos
- Muchos a muchos
¿Qué es una entidad?
Es un objeto o concepto real del que se desea guardar información en una base de datos.
Ejemplo: un cliente, un producto o un empleado.
¿Qué hace el SET en SQL?
Se usa para asignar un valor a una variable o modificar valores en una tabla.
Ejemplo:
SET @nombre = 'Juan';
¿Para qué sirve el backup? Sirve para hacer una copia de seguridad de la base de datos, que permite restaurarla en caso de pérdida, daño o error.
¿Qué es un trigger y qué aspectos de seguridad tiene como ventaja?
Un trigger es un bloque de código que se ejecuta automáticamente cuando ocurre una acción como INSERT, UPDATE o DELETE.
Ventajas en seguridad:
- Controla o bloquea cambios indebidos.
- Impone reglas automáticas.
- Lleva un registro de quién hizo qué (auditoría).
Diferencia entre CROSS JOIN y JOIN (INNER JOIN):
CROSS JOIN: combina todas las filas de una tabla con todas las de otra (producto cartesiano).
Ejemplo: 3 filas × 2 filas = 6 combinaciones.INNER JOIN: une las tablas solo donde hay coincidencia en una columna común.
Es más eficiente y común que elCROSS JOIN.
¿Para qué sirve el CAST en SQL?
Sirve para convertir un valor de un tipo de dato a otro. Ejemplo: convertir un número a texto o una fecha a string.
SELECT CAST(123 AS VARCHAR);
/ Más Información
Lenguajes de programación
[[C Sharp]][[Java]][[JavaScript]][[Python]]